Ulrich Drepper Red Hat, Inc. November 1998
Traditionally the handling of critical errors in a program is very weak in Unix environments. These situations are normally handled by the kernel generating a signal which, if not caught by the programs, kills the programs. What remains is in the best case a core dump which can be used in port-mortem debugging sessions.
This certainly is not the most comfortable working environment for a programmer and it is even less desirable for users (ok, a part of the user group). Assume a long-running application which after a long time suddenly crashes. If the application cannot be restarted some saved data one has to restart it after fixing the bug. The later might not always be possible to do since the core file might not contain all the information.
In LISP environments there is a better solution since the early days. Whenever the programs comes accross an error the user gets the opportunity to correct the error and resume the application. Maybe some variables must be corrected/reset but this is also no problem. Correcting the error might mean correcting an invalid parameter, an invalid variable value or even replacing missing and wrong function implementations. Something C programmers can only dream of!
The design of a runtime environment presented here will provide an experienced programmer with similar possibilities. We speak about C programmers so far, but there is no reason why this should not be applicable to C++, FORTRAN, etc. This system is most probably nothing for novice programmers or even non-programmers but is better than nothing.
Problems in a program which cause it to terminate normally are:
This list is incomplete but should cover the most important cases. This means that we are able to handle these error at user level since it is only necessary to install appropriate handler for these signals. The function called in this case can initiate the debugging.
But this is easier said then done. Since these signals are normally not generated when the program is running fine we cannot assume that we can work as usual. E.g., an SIGFAULT signal can be generated if the data for the memory allocation functions (malloc etc) got corrupted. But this means we cannot use these functions in the signal handler as well. Since we always must assume the worst case the functionality we can safely use in signal handlers is very limited. In fact, only system calls and operations not involving dynamically allocated memeory or static data can be used.
The consequence of this is that the bulk of the code for the debug server must be in a completely different process. The signal handler must only be used for communication between the debug server and the application. There might be some other tasks which can be performed but one must be really careful.
So far we mentioned only one possibility to call the debug server: while intercepting a signal. But there might be situations where one wants to call the debugger explicitly. E.g., if a function does not implement a certain operation so far since one expects this not to be necessary in the moment one might would like to be notified about this. Then one either could work around this limitation or even provide now a complete implementation of the function.
There are many possible implementations of this. I'm currently thinking about one which does not involve changes to the underlying operation system. If changes are an option the implementation could be improved in quality but the basic functionality probably will remain similar.
The implementation will consist of three parts:
The application normally will interact with the debugging code normally only indirectly. During startup the debugging code will register some signal handlers and if the program does not deal with them itself it will never realize there is this extra functionality available.
But there are also situations when the program knows something is wrong without crashing. In this situation it is desirable to have a way to ask for assistance which can happen by calling the debugging code which itself calls the debug server which in turn makes itself visible to the user using the frontend. The alerted user then can do whatever is necessary.
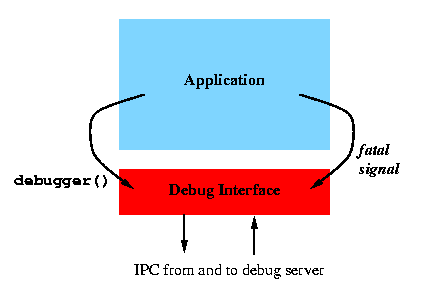
The structure of the debugging code in the application therefore looks somewhat like this:
It is easy to ensure that there is always a function debugger() which by default does nothing or terminates the program. If the debug interface is available it will hand over control to the debug server.
On modern system (i.e., those using ELF) it will be possible to use this debugging functionality even if the necessary functionality wasn't linked in at program creation time. Using LD_PRELOAD one can add arbitrary code which is completely sufficent in this case. So one can enable debugging even after somebody decided to not put in the code by default. This will always be the default since in most cases the user is not interested to see the debugger popping up for every crashing program.
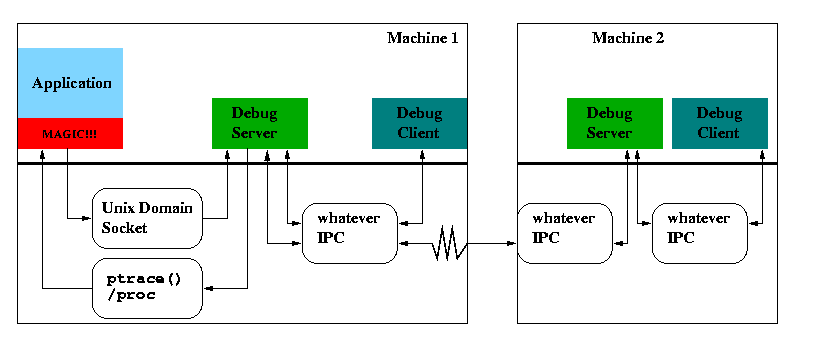
The debug server has two interfaces: one to the applications which need attention and the other to the user interface. These interfaces very much determine the way the debugserver has to be implemented.
First to the interface to the running application. The debug server must have complete control over the application. This can happen in several ways:
The last two points in this list require appropriate permissions to perform the job. The Unix security mechanisms do not allow the use of these interfaces if the caller is not proviledged. I.e., either the debug server runs with the same UID as the application or the debug server is running with super user permissions. (Or in modern OSes with POSIX capabilities, the debug server has the appropriate capabilities for these debugging functions enabled).
More of concern is the IPC connection from the debugging code to the debug server. This connection has to be used at least once during the initiation of the debugging. The effects on the design is fundamental: this IPC connection must allow authentification. The authentification must not be complex (i.e., we must not depend on password protection etc). Instead we must use a mechanism which allows authentification without user intervention. Fortunately thi exists.
When using Unix domain sockets its is possible to pass credentials together with the data to the receiving process. The credential data is verified by the kernel and therefore cannot be forged (unless there is an exploitable bug in the kernel, of course). The initial contact between the application and the debug server therefore has to use the credential passing mechanism. This way the debug server is able to determine whether the request for debugging is coming from the right source.
It might be useful to show why this authentification is so important. Assume no authentification is performed. Then it would be possible for every process to contact the debug server. Since the debug server might be running with a different UID (maybe even as super user) it would be possible for the caller to examine each and every process and its memory if only the debug server has the appropriate permisssions. Since the mechanism we want to implement requires requests to debug a certain process only from a process itself it is possible to test for matching PIDs. But it should be left as an option to decide about the permissions also based on the UID or GID.
The requirements of the connection to the user interface are not so severe but nevertheless should be considered before any design decisions. Here we have in general no security considerations. But the freedom of the user would be greatly extended if the location of the frontend could be independent of the location of the debug server. I.e., using communication means which can reach arbitrary processes on arbitrary machines would allow to debug a process from any available system.
Such a communication mechanism provide normal Internet sockets. By using TCP/IP connections (or similar mechanisms) the debug server can forward the information to a process on another machine which itself starts the user interface. The process which gets the information forwarded to probably is just another copy of the debug server.
It is not necessary to tell much about this here since it is an own project. It should be possible to connect a full debugger (e.g., gdb) to the debug server. The remote debugging capabilities of the debugger could be exploited if the protocol used by the debugger is understood by the debug serevr.
But it should not be required to have such a sophisticated user interface. Often the only thing the user wants is to examine some variables, memory location etc. Such a client would be much lighter and therefore the interface to the user interface should not only allow complex debuggers to be used.
A complete picture of the system could look like this:
Assume a large number of machines running the same program providing some essential service. To ensure high uptime rates the machines and processes should be monitored. Problems should be reported to an operator which then can take appropriate actions.
This can certainly be achieved using existing techniques as well. A simple watchdog process could report the problem and the operator can take appropriate actions. But in this case the only thing the operator can do is to restart the program while perhaps having lost some data.
When using the debug server it would be possible to perform some work before the process dies. I.e., the data is not yet lost. Maybe it is even possible to revive the process which might be possible in case no corruption of internal data happened.
A picture to illustrate this:

Please note that the machines executing the programs could also be some embedded computers. There are simple TCP/IP stacks available for those platforms and therfore contacting the operator's machine would be possible.
In many situations it is crucial to have absolutely no downtime. Or, restarting a process would take to much time since building up all the data structures takes a lot of time. An example is BIND.
In situations like this is would be preferrable to be able to debug the program instead of having it dying. A programmer who knows the details about the program can be able to decide whether internal data structures are damaged and if necesary repair them. E.g., the libc could contain support for investigating the malloc() data structure, show the problems and let the user modify the damaged places.
It would also be possible to replace functions in the binary. If during the debugging it is recognized that a function has a problem the source code locally (at the machine the user uses) can be modified, the function can be compiled and the binary can be transfered to the failing process, replacing the one function. This can be done by copying the object file, performing the relocations and adding an unconditional jump from the original address of the function to the new position. If the function is reached using PLT entries there is an even cleaner way: only substitute the address in the PLT.
The central part, the debug server, can probably be build on top of CygMon. The communication with the application must be written from scratch since there is so far no adequately simple and secure protocol. The protocol to the user interface on the other hand can be chosen to be the one gdb already supported by gdb. Extracting the functionality from the gdbserver application should be doable.
To what extend the functionality of CygMon has to be extended remains to be evaluated. The functionality is in any case already available in gdb.
The debugging interface to the application is rather simple. At least for now. It can be extended later to perform more difficult tasks (such as the interface to the dynamic linker or repairing malloc() data structures.
The user interface can either consist of an adapted gdb or of a simple command line driven program. Again, CygMon already provides much of the functionality.
The complete functionality probably can only be implemented if we have complete control over the entire execution environment. This would include Linux (of course :-) and also embedded platforms. On other Unix platforms it will be possible to implement as much functionality as is available in gdb.